WHAT ORDINARY ELECTRONIC DICTIONARIES
CANNOT DO.
A PROJECT FOR A HYPERMEDIA MULTI-ACCESS
ENGLISH-POLISH DICTIONARY
The main thrust of my project, is the idea of multi-access. In
a nutshell, this means that virtually every bit of information
inherent in the lexical database used for the construction of the
dictionary is available - in a suitably friendly form - to the
user of the CD-ROM for active search, i.e. as a search key.
In the existing computer dictionaries only a small subset of the
relevant information can be so used: spelling (with or without
wildcards), subject field, part-of-speech (sometimes), and the
usually rather frustrating, completely undifferentiated 'whole-text'
search, which is bound to identify a load of useless (mis-)hits.
At the same time, there are many 'things' which standard computer-readable
dictionaries cannot do, not because they lack the necessary
information, but rather because they do not have the mechanisms
which would be able to use it to the full advantage of the
learner. The following is a sample list of such 'things' relevant
mostly to a foreign (Polish) learner of English.
Ordinary machine-readable dictionaries cannot:
- list (and say) words which are pronounced in some
particular way, for example with a given number of
syllables, or with a given stress, or containing
specified sounds, or differing between British and
American accents, etc.
- list words with particular collocates: make a
mistake will probably be listed under make,
with make the bead and other such idioms, and/or
under mistake, with by mistake etc., but
what about bad, serious, terrible mistake, and
what about mistakes creep in, occur, and what
other nouns do we do something by ...?
- generate a concordance of selected word(s) in
their particular context using the full text of the
dictionary, example sentences in particular, a feature
especially advantageous in a learner's dictionary.
- list words with a particular 'part-of-speech':
nouns, verbs, adjectives, adverbs, prepositions, or with
a particular morphosyntactic category, e.g. gender, case,
number (e.g. pluralia tanta, irregular plurals, etc.), or
with a particular derivational composition, e.g.
compounds.
- list heterographic homophones (hoarse - horse),
antonyms, (L1-sensitive) paronyms (e.g. dock
with dog), hypernyms (mistake --->
failure, dog ---> canine), hyponyms
(mistake --> blunder, faux pas, goof, slip-up,
oversight, typo), and indeed most other -nyms,
with the exception of synonyms in some electronic
dictionaries.
- list words within or without a particular frequency,
familiarity or polysemy band, e.g. very common, or
all except very rare, or all but the most
polysemous.
- list words which are known to be especially difficult
to the given L1 learners, orthographically, phonetically,
morphosyntactically, semantically or pragmatically.
- list words characteristic or unique to certain varieties,
dialects (e.g. British vs American), styles, jargons,
vocabulary strata (e.g. loanwords from language X), etc.
- list words whose associated visual representations
(in a multimedia dictionary) meet certain conditions, e.g.
'round and red on green background': rose, cherry,
tomato, beef patty, blood drop, ruby on green velvet,
etc.
- combine the above criteria in multiple Boolean
searches, e.g. "Which nominal compounds spell
with a space (rather than a hyphen) and are stressed on
the first word?" (answer: charnel house, zip code,
zoo suit, according to the electronic version of
Hornby's Oxford Advanced Learner's Dictionary).
AN EXAMPLE OF A SIMPLE MULTI-ACCESS
ENGLISH-POLISH DICTIONARY
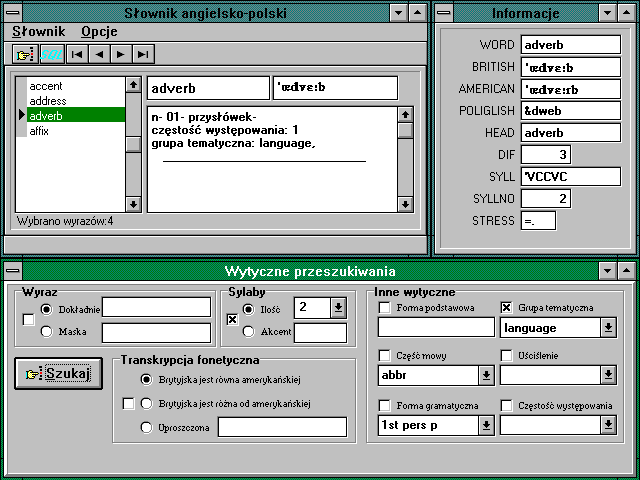
The following is an example of a working implementation of a
functionally very restricted simple MAD which I demonstrated at a
computational linguistics conference in Bergen in 1996 (see Bibliography of the project). Only the
letter 'A' is implemented containing 3761 wordforms or 1994 head
entries. This example of a MAD page shows (in the top left-hand
window) the four entries meeting the conjunction of two
conditions: (a) semantic field - language and (b) syllable
length - 2. Of the four, adverb is selected, and a
fair amount of lexicographic information concerning this entry is
displayed, including:
- in the top left-hand window: part of speech (noun),
Polish translation (przysłówek),
raw frequency of occurrence (1), semantic field (language),
phonetic transcription (British pronunciation).
- in the top right-hand window: spelling, British and
American pronunciation, simplified 'polglish'
transcription, phonetic difficulty index (3, i.e. not
very difficult), syllabic composition with stress mark,
syllable number and stress pattern (strong,weak).
- in the bottom window search criteria can be selected,
including wildcard orthographic search, part-of-speech,
inflectional form, and others. It is here that the
currently selected search criteria have crossed windows.
The main search button ('Szukaj') is also located here.
Bibliography of the project:
- 1994."Phonetic-access dictionaries with L1-based simplified
transcription". Poster presented at the 6th Euralex International
Congress, Amsterdam, September 1994.
- 1994."Phonetic access dictionaries in EFL: from vision to
project". Nordlyd 21.33-41.
- 1994."Beyond the year 2000: phonetic access dictionaries (with
word-frequency information) in EFL". System 22.4.509-23. [one-page
abstract in Cambridge Language Reference News].
- 1996."Słowniki z dostępem
fonetycznym w nauce języka angielskiego". In Z.Vetulani, W.Abramowicz
& G.Vetulani (eds).1996. Język i technologia. Warszawa:
Akademicka Oficyna Wydawnicza PLJ. 168-171.
- 1996. "EFL Wordstation". In A.Lindebjerg, E.S.Ore &
Ć .Reigem (eds). 1996. ALLC-ACH ‘96
Conference Abstracts. Bergen: Norwegian Computing Centre for the
Humanities. 243-246. Also in W.Skrzypczak (ed.).1996. New technologies
in language education. Toruń:
Department of English, Nicholas Copernicus University. (abstract here)
- 1998. "Słownik z dostępem
fonetycznym w nauce języka angielskiego". Edukacja Medialna 7.42-44.
- 1998. "When dictionaries talk: proununciation in EFL MM
MRDs". In T.Ottmann & I.Tomek (eds).1998. Proceedings of
ED-MEDIA/ED-TELECOM 98, World Conference on Educational Multimedia and
Hypermedia & World Conference on Educational Telecommunications,
Freiburg, Germany, June 20-25, 1998. Vol. 2. 1298-1304. (abstract here)
- 1998. "Phonetic access in OED2 on CD-ROM". In L.Hunyadi et
al. (eds). 1998. ALLC/ACH'98 Conference Abstracts, Debrecen, Hungary, 5-10
July 1998. 158-161. (abstract here)
- 1998. "Can EFL MRDs teach pronunciation?" . In T.Fontenelle
et al. (eds). 1998. Euralex'98 proceedings. Liege: University of
Liege, English and Dutch Departments. 271-77. (abstract here)
- 1998. "Słownik z dostępem fonetycznym w nauce języka angielskiego".
Edukacja Medialna 7.42-44.
- 1998. "Electronic dictionaries and encyclopedias — promises and
dangers". In W.Strykowski (ed.).1998. Media a edukacja II. Poznań: eMPi2. 543-56.(abstract here)
- 1999. Pronunciation in EFL Machine-Readable Dictionaries. Poznań: Motivex. (abstract here)
- 2000. "Ease, speed and access: attitude and experience of computer dictionaries". In W.Strykowski (ed.). 2000. Media a
edukacja III. Poznań: eMPi2. 459-67. (abstract here)
- 2002. "The challenge of electronic learners' dictionaries".Teaching English with Technology 2.1. (abstract here and full paper here).